
どうも日頃、Xでツイートをしているタケイ(@pcefancom)です。
最近はまっているのが、NotebookLMです。
自分が指定したソースだけを勉強して答えてくれる生成AIで、これまでの自分の発言を全部取り込んで、自分botを作っています。
今週、X(Twitter)の2010年からのツイートを全部保存、NotebookLMに読み込ませることが出来ましたので、その方法を紹介します!
目次
NotebookLMにXの全ツイートを読み込ませる方法
順番に紹介していきます。
作業は1日以上かかるので、気長に読んでください。
作業に必要なもの|X、パソコン、GeminiまたはChatGPT、NotebookLM|所要時間5分
まず、作業に必要なものを紹介します。
始める前に以下のものは用意しておいてください。
- X|ツイートを取得するために必要。無料でも大丈夫です
- パソコン|WindowsでもMacでもChromebookでも大丈夫です。この記事はWindows基準で書いています。
- GeminiまたはChatGPT|ツイートデータを編集するために使います
- NotebookLM|当然必要です
(1)X|設定で全履歴のデータ取得を依頼する|所要時間24時間
まず最初にXでツイートの全履歴のデータ取得を依頼します。
設定から
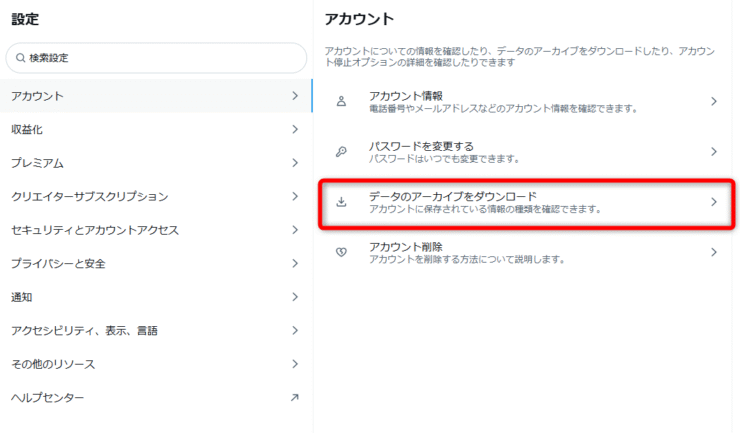
データダウンロードのリクエストボタンがあるので押します。
これでリクエストがスタートします。
注意なのが、すぐにデータをダウンロードできるわけではないことですね。
アカウントを作ってからの全ツイート、メディアのダウンロードとなるためそれなりに時間がかかるようです。

タケイ
ちなみに私の場合、24時間まるまるかかりました。
(2)X|ダウンロードできるまで24時間待つ|所要時間5分
ダウンロードできるようになるまで待ちます。
リクエストが完了してダウンロードできるようになるとボタンの表示が
「アーカイブにダウンロード」
に変わります。
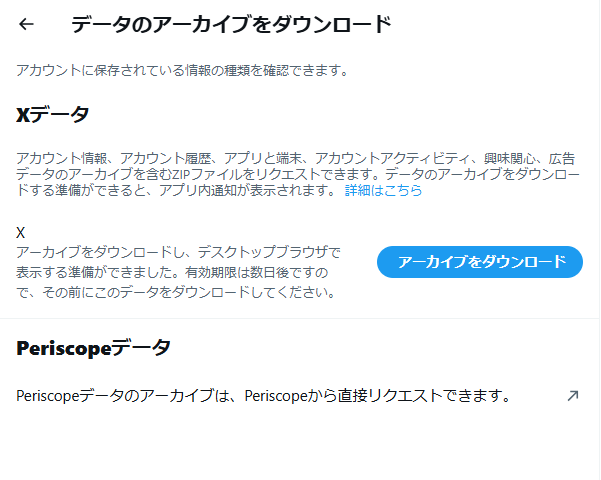
このボタンを押してファイルをダウンロードします。
(3)パソコン|全ツイートの履歴をダウンロードする|所要時間5分
ちなみにダウンロードするときはパソコンを使いましょう、
何万ツイートもしていると、数ギガのファイルになっていると思います。
容量が大きいですし、この後の作業はパソコンで行うのでダウンロードもパソコンでやった方がお勧めです。
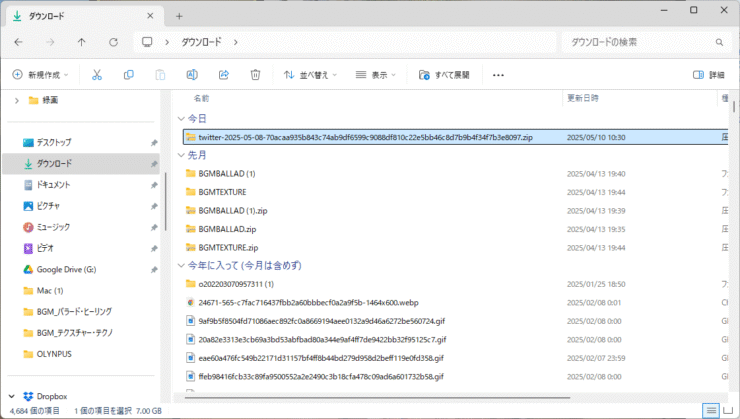
ファイルはZip形式となっています。
タケイ
私の場合、ファイルサイズは7GBほどでした。
(4)パソコン|全ツイートファイルを解凍する|所要時間5分
ダウンロードができたら解凍しましょう。
解凍すると「日付+ハッシュ値」のようなフォルダができていると思います。
エクスプローラーやファイルアプリで中身を確認してみてください。
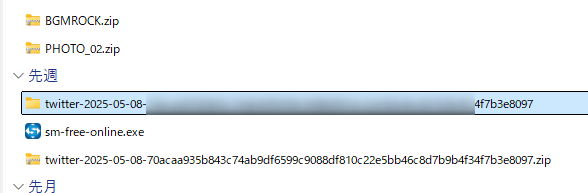
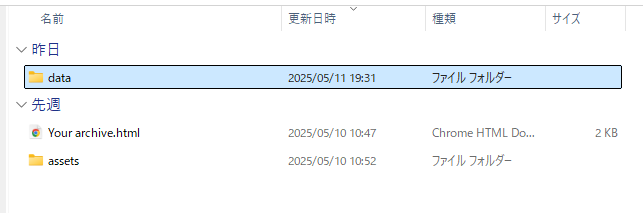
中身は
- assets|映像や写真、フォントなどが格納
- data|ツイートのJSONデータが入っている
- archive.html|ローカルのブラウザで全ツイートが見られるようになっている
となっています。
archive.htmlをみると懐かしさ満点でお勧めです。
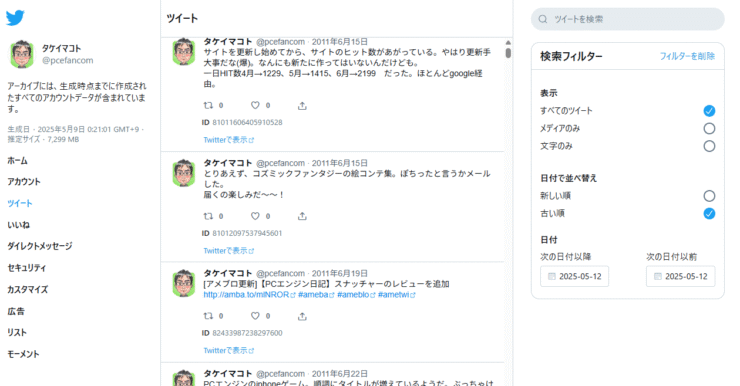
(5)パソコン|ツイートデータを確認する|所要時間5分
ツイートデータを確認してみましょう。
テキストは「tweets.js」というファイルに格納されています。
ファイルは「data」フォルダ内に入っていルはずです。
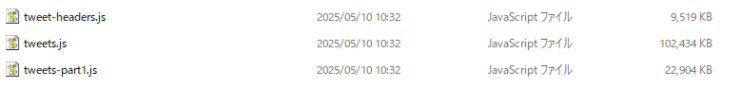
ちなみに一つのファイルサイズは100MBが上限となっているようで、サイズを超えた分は
tweets-part1.js
tweets-part2.js
と枝分かれしていくようですね。
ツイート数が多い方はこのファイルがいくつかできていると思います。
(6)パソコン|ツイートデータをJSONからマークダウン形式に変換する|所要時間1~5時間

このファイルをマークダウン形式に変換していきます。
tweets.jsというファイルは「JSON」という形式で作られているのですが、NotebookLMでは対応していません。
テキスト系のデータはマークダウン形式「.md」にする必要あります。
どうやって変換するか?
ですが、手っ取り早いのはtweets.jsをGeminiやChatGPTにアップロード、プロンプトで
「アップロードしたファイルはXのアーカイブ tweets.js です。NotebookLMで読み込めるようにマークダウン形式に書き換えてください」
とすればすぐにマークダウン形式に変換してくれます。
ただ、困るのはファイルサイズが25MB以上になる場合。
ChatGPTだとアップロードサイズの上限が25MB、Geminiだと100MBなので人によっては制限に引っかかってしまいます。
私も引っかかったので、そこはPower shellスクリプトでパソコンで変換することにしました。
スクリプトもGeminiにつくってもらったので、以下に貼っておきます。
# --- 設定項目 ---
# 入力する tweets.js ファイルのパス (このスクリプトと同じフォルダにあることを想定)
$inputFile = "tweets.js"
# 出力する Markdown ファイルのパス (このスクリプトと同じフォルダに出力)
$outputFile = "tweets-after.md"
# --- 設定項目ここまで ---
# --- スクリプトの場所を取得 ---
$scriptDirectory = $PSScriptRoot
$inputFilePath = Join-Path $scriptDirectory $inputFile
$outputFilePath = Join-Path $scriptDirectory $outputFile
# --- 初期メッセージ ---
Write-Host "処理を開始します..."
Write-Host "入力ファイル: $inputFilePath"
Write-Host "出力ファイル: $outputFilePath"
# --- 入力ファイルの存在確認 ---
if (-not (Test-Path $inputFilePath)) {
Write-Error "エラー: 入力ファイル '$inputFilePath' が見つかりません。ファイル名とパスを確認してください。"
exit 1
}
# --- ファイル内容の読み込みと前処理 ---
Write-Host "入力ファイルを読み込んでいます..."
$jsonString = $null # エラー時に参照できるよう初期化
try {
# ファイル全体を単一の文字列として読み込む
$fileContent = Get-Content -Path $inputFilePath -Raw -Encoding UTF8
Write-Host "--- デバッグ情報 ---"
Write-Host "読み込んだファイル内容の先頭150文字: $($fileContent.Substring(0, [System.Math]::Min($fileContent.Length, 150)))"
Write-Host "読み込んだファイル内容の末尾150文字: $($fileContent.Substring([System.Math]::Max(0, $fileContent.Length - 150)))"
Write-Host "--------------------"
# "window.YTD.tweets.partX = " のようなプレフィックスを削除
# part の後の数字は0回以上可変に対応するため正規表現を使用 (\d*)
$jsonString = $fileContent -replace '^\s*window\.YTD\.tweets\.part\d*\s*=\s*', ''
# 末尾のセミコロンを削除 (存在する場合)
$jsonString = $jsonString.TrimEnd(";")
Write-Host "--- デバッグ情報 ---"
Write-Host "プレフィックス除去後のJSON文字列の先頭150文字: $($jsonString.Substring(0, [System.Math]::Min($jsonString.Length, 150)))"
Write-Host "プレフィックス除去後のJSON文字列の末尾150文字: $($jsonString.Substring([System.Math]::Max(0, $jsonString.Length - 150)))"
if ($jsonString.TrimStart() -notmatch '^\[') { # 正規表現で開始括弧をチェック
Write-Warning "警告: プレフィックス除去後のJSON文字列が '[' で始まっていません。形式が予期したものと異なる可能性があります。"
}
if (-not $jsonString.TrimEnd().EndsWith("]")) {
Write-Warning "警告: プレフィックス除去後のJSON文字列が ']' で終わっていません。形式が予期したものと異なるか、ファイルが途中で途切れている可能性があります。"
}
Write-Host "--------------------"
# JSON文字列をPowerShellオブジェクトに変換
Write-Host "JSONデータを解析しています..."
$tweetsData = $jsonString | ConvertFrom-Json # -Depth 100 を削除
} catch {
Write-Error "エラー: ファイルの読み込みまたはJSONの解析中にエラーが発生しました。"
Write-Error "詳細: $($_.Exception.Message)"
if ($jsonString -ne $null) {
Write-Host "--- エラー発生時のJSON文字列 (先頭最大500文字) ---"
Write-Host $jsonString.Substring(0, [System.Math]::Min($jsonString.Length, 500))
Write-Host "--------------------------------------------------"
}
exit 1
}
if ($null -eq $tweetsData) {
Write-Error "エラー: JSONデータの解析に失敗したか、データが空です。"
exit 1
}
# --- Markdownコンテンツの生成 ---
Write-Host "Markdownコンテンツを生成しています..."
$markdownContent = @()
$markdownContent += "# ツイートデータ ($inputFile)"
$markdownContent += "" # 空行
$tweetCounter = 0
foreach ($tweetEntry in $tweetsData) {
$tweetCounter++
$tweet = $tweetEntry.tweet # ツイートオブジェクトを取得
$markdownContent += "## ツイート $tweetCounter"
$markdownContent += ""
$markdownContent += "- **ID:** $($tweet.id_str)"
$markdownContent += "- **作成日時:** $($tweet.created_at)"
# 本文 (改行をMarkdownの改行に変換)
$fullText = $tweet.full_text -replace "`r`n", "`n" -replace "`n", "<br>"
$markdownContent += "- **本文:**<br>$fullText" # <br>タグで改行を表現
# いいね数
if ($null -ne $tweet.favorite_count) {
$markdownContent += "- **いいね:** $($tweet.favorite_count)"
}
# リツイート数
if ($null -ne $tweet.retweet_count) {
$markdownContent += "- **リツイート:** $($tweet.retweet_count)"
}
# 言語
if ($null -ne $tweet.lang) {
$markdownContent += "- **言語:** $($tweet.lang)"
}
# ソース (HTMLタグを除去)
if ($null -ne $tweet.source) {
$sourceText = $tweet.source -replace '<[^>]+>', ''
$markdownContent += "- **ソース:** $sourceText"
}
# 返信先情報
if ($null -ne $tweet.in_reply_to_status_id_str) {
$markdownContent += "- **返信先ツイートID:** $($tweet.in_reply_to_status_id_str)"
}
if ($null -ne $tweet.in_reply_to_user_id_str) {
$replyToScreenName = ""
if ($tweet.entities.user_mentions) {
$replyMention = $tweet.entities.user_mentions | Where-Object {$_.id_str -eq $tweet.in_reply_to_user_id_str} | Select-Object -First 1
if ($replyMention) {
$replyToScreenName = "@$($replyMention.screen_name) ($($replyMention.name))"
} else {
$replyToScreenName = "@$($tweet.in_reply_to_screen_name)" # フォールバック
}
} else {
$replyToScreenName = "@$($tweet.in_reply_to_screen_name)" # フォールバック
}
$markdownContent += "- **返信先ユーザー:** $replyToScreenName"
}
# ハッシュタグ
if ($tweet.entities.hashtags -and $tweet.entities.hashtags.Count -gt 0) {
$markdownContent += "- **ハッシュタグ:**"
foreach ($hashtag in $tweet.entities.hashtags) {
$markdownContent += " - $($hashtag.text)"
}
}
# メンション
if ($tweet.entities.user_mentions -and $tweet.entities.user_mentions.Count -gt 0) {
$markdownContent += "- **メンション:**"
foreach ($mention in $tweet.entities.user_mentions) {
# 返信先として既に表示されている場合はスキップ (オプション)
# if ($null -eq $tweet.in_reply_to_user_id_str -or $mention.id_str -ne $tweet.in_reply_to_user_id_str) {
$markdownContent += " - @$($mention.screen_name) ($($mention.name))"
# }
}
}
# URL
if ($tweet.entities.urls -and $tweet.entities.urls.Count -gt 0) {
$markdownContent += "- **URL:**"
foreach ($url in $tweet.entities.urls) {
$markdownContent += " - [$($url.display_url)]($($url.expanded_url))"
}
}
# メディア (画像、動画など)
if ($tweet.extended_entities -and $tweet.extended_entities.media -and $tweet.extended_entities.media.Count -gt 0) {
$markdownContent += "- **メディア:**"
foreach ($media_item in $tweet.extended_entities.media) {
if ($media_item.type -eq "photo") {
# Markdownの画像表示は ![]() ですが、NotebookLMでの表示を考慮し、リンクとして提供
$markdownContent += " - [画像: $($media_item.media_url_https)]($($media_item.expanded_url)) (URL: $($media_item.media_url_https))"
} elseif ($media_item.type -eq "video") {
$videoUrl = ""
if ($media_item.video_info.variants.Count -gt 0){
# 最もビットレートが高いものを選択 (あるいは content_type が 'video/mp4' のもの)
$bestVariant = $media_item.video_info.variants | Where-Object {$_.content_type -eq "video/mp4"} | Sort-Object bitrate -Descending | Select-Object -First 1
if ($bestVariant) {
$videoUrl = $bestVariant.url
} else { # mp4 がなければ最初のものを
$videoUrl = $media_item.video_info.variants[0].url
}
}
$markdownContent += " - [動画: $($media_item.media_url_https)]($($media_item.expanded_url)) (URL: $videoUrl)"
} elseif ($media_item.type -eq "animated_gif") {
$markdownContent += " - [GIFアニメ: $($media_item.media_url_https)]($($media_item.expanded_url)) (URL: $($media_item.video_info.variants[0].url))"
} else {
$markdownContent += " - [$($media_item.type): $($media_item.media_url_https)]($($media_item.expanded_url))"
}
}
}
$markdownContent += "" # セクションの終わりに空行
$markdownContent += "---" # ツイート間の区切り線
$markdownContent += ""
}
# --- Markdownファイルへの書き出し ---
Write-Host "Markdownファイルに書き出しています..."
try {
$markdownContent | Set-Content -Path $outputFilePath -Encoding UTF8
Write-Host "処理が正常に完了しました。出力ファイル: $outputFilePath"
} catch {
Write-Error "エラー: Markdownファイルへの書き出し中にエラーが発生しました。"
Write-Error "詳細: $($_.Exception.Message)"
exit 1
}
Write-Host "スクリプトの実行が終了しました。"
使い方は、
- tweets.jsがあるフォルダにスクリプトを配置
- Power shellを管理者として実行
- ./スクリプト名
とうつだけです。
変換が終わると同じフォルダに.md形式にファイルができあがります。
ちなみに処理時間ですが、100MBのツイートファイルで5時間かかりました。
20MBで1時間ほどかかりましたので、ファイルが2つある方は半日以上かかると見込んでおいた方がいいです。
(7)パソコン|Notebook LMのファイル制限に引っかからないようにツイートデータを分割する|所要時間5分
マークダウン形式にできたら、今度はファイルをNotebookLMの制限に引っかからないように分割していきます。
NotebookLMでは100MBというサイズ制限にくわえて1ファイルの言語数が500,000という制限もあります。
そのままアップロードしてしまうと、エラーになってしまいます。
エラーを回避するために480,000語ごとにマークダウン形式のファイルを分割するPower shellスクリプトも作りましたので、よかったら使ってみてください。
インプットファイル名のところは読み込むファイル名に変えてくださいね。
# --- 設定項目 ---
# 分割したいMarkdownファイル名を指定してください。
# このスクリプトと同じフォルダにファイルがあることを想定しています。
$inputMarkdownFile = "tweets-part1.md"
# 1ファイルあたりの目標語数制限 (NotebookLMの制限を考慮し、少し余裕を持たせる)
# 日本語の場合、1文字を約1語として簡易的に扱う
$targetWordLimitPerFile = 480000
# --- 設定項目ここまで ---
# --- スクリプトの場所とファイルパスの設定 ---
$scriptDirectory = $PSScriptRoot
$inputFilePath = Join-Path $scriptDirectory $inputMarkdownFile
# 出力ファイルのプレフィックスを決定 (入力ファイル名から拡張子を除いたものを使用)
$inputFileBaseName = [System.IO.Path]::GetFileNameWithoutExtension($inputMarkdownFile)
$outputFilePrefixPath = Join-Path $scriptDirectory "${inputFileBaseName}_chunk" # パスとプレフィックスを結合
# --- 初期メッセージ ---
Write-Host "処理を開始します..."
Write-Host "入力ファイル: $inputFilePath"
Write-Host "1ファイルあたりの目標語数: $targetWordLimitPerFile"
# --- 入力ファイルの存在確認 ---
if (-not (Test-Path $inputFilePath)) {
Write-Error "エラー: 入力ファイル '$inputFilePath' が見つかりません。ファイル名とパスを確認してください。"
exit 1
}
# --- ファイル内容の読み込みと情報収集 ---
Write-Host "入力ファイルを読み込んでいます..."
try {
# ファイルの全行を読み込む
$allLines = Get-Content -Path $inputFilePath -Encoding UTF8
# ファイル全体のコンテンツを文字列として取得 (文字数カウント用)
$fileContentString = Get-Content -Path $inputFilePath -Raw -Encoding UTF8
} catch {
Write-Error "エラー: ファイル '$inputFilePath' の読み込み中に問題が発生しました。"
Write-Error "詳細: $($_.Exception.Message)"
exit 1
}
$totalLines = $allLines.Count
$totalCharacters = $fileContentString.Length
Write-Host "総行数: $totalLines"
Write-Host "総文字数 (≒総語数として扱う): $totalCharacters"
# ファイルが空の場合は処理を終了
if ($totalLines -eq 0) {
Write-Warning "警告: 入力ファイルが空です。分割処理は行われません。"
exit
}
# --- 分割数の計算 ---
$numberOfChunks = 1 # デフォルトは1 (分割なし)
if ($totalCharacters -gt $targetWordLimitPerFile) {
# 1行あたりの平均文字数(語数)を計算 (0除算を避ける)
$averageCharsPerLine = if ($totalLines -gt 0) { $totalCharacters / $totalLines } else { $totalCharacters }
if ($averageCharsPerLine -eq 0) { $averageCharsPerLine = 1 } # 0除算を避けるための最小値
# 1ファイルに含める目標行数を計算
$targetLinesPerFile = [System.Math]::Floor($targetWordLimitPerFile / $averageCharsPerLine)
if ($targetLinesPerFile -lt 1) { $targetLinesPerFile = 1 } # 最小でも1行は含む
# 必要な分割数を計算 (小数点以下切り上げ)
$numberOfChunks = [System.Math]::Ceiling($totalLines / $targetLinesPerFile)
}
Write-Host "計算された分割数: $numberOfChunks"
# --- 1ファイルあたりの行数を計算 ---
# 総行数を計算された分割数で割り、小数点以下を切り上げる
$linesPerChunk = [System.Math]::Ceiling($totalLines / $numberOfChunks)
Write-Host "1ファイルあたりの最大行数: $linesPerChunk"
# --- ファイル分割処理 ---
Write-Host "ファイルの分割処理を開始します..."
for ($i = 0; $i -lt $numberOfChunks; $i++) {
# 現在のチャンクの開始行インデックス (0から始まる)
$startIndex = $i * $linesPerChunk
# 開始インデックスが総行数以上であれば、全ての行が処理されたとみなしループを抜ける
if ($startIndex -ge $totalLines) {
Write-Host "全ての行が処理されました。これ以上分割ファイルは作成されません。"
break
}
# 現在のチャンクの終了行インデックス
$endIndex = (($i + 1) * $linesPerChunk) - 1
# 終了インデックスが総行数を超えないように調整
if ($endIndex -ge $totalLines) {
$endIndex = $totalLines - 1
}
# 分割する行の範囲を取得
# PowerShellの配列スライスは $array[開始インデックス..終了インデックス]
$chunkLines = $allLines[$startIndex..$endIndex]
# 出力ファイル名を生成 (例: tweets-part1_chunk_1.md)
$outputChunkFileName = "${outputFilePrefixPath}_$($i+1).md"
# ファイルに書き出し
try {
Set-Content -Path $outputChunkFileName -Value $chunkLines -Encoding UTF8
Write-Host "ファイル '$outputChunkFileName' を作成しました。($($chunkLines.Count) 行)"
} catch {
Write-Error "エラー: ファイル '$outputChunkFileName' の書き出し中に問題が発生しました。"
Write-Error "詳細: $($_.Exception.Message)"
}
}
Write-Host "スクリプトの実行が終了しました。"
こちらの処理は1分で終わりました。
処理が終わると、アップロードできるファイルに分割されたファイルができあがります。
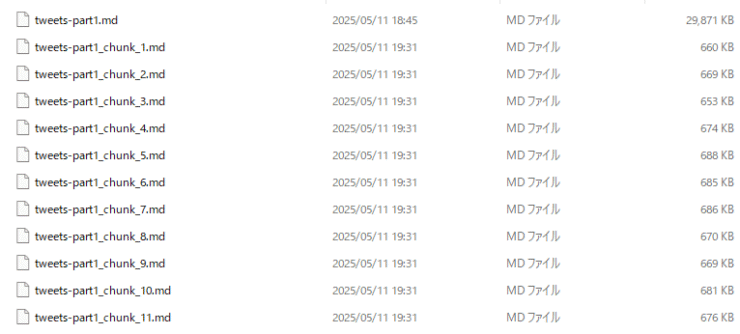
ちなみにファイル数は25くらい、1ファイルあたり660KBとなっていました。
(8)NotebookLM|分割したマークダウン形式のツイートデータをアップロードする|所要時間5分
これでアップロードの準備ができました。
NotebookLMを開いて、マークダウン形式のファイルをアップロードします。
ファイルをまとめてアップロードします。
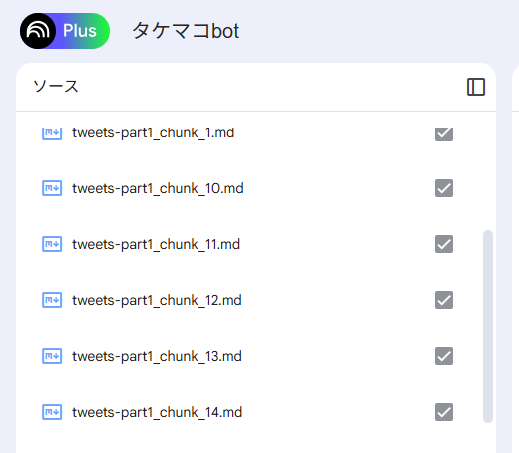
ソースにチェックマークがつけば読み込み完了です。
(9)NotebookLM|自分の発言について質問してみる
これで自分のツイートを反映した、自分Botチャットツールが完成しました!
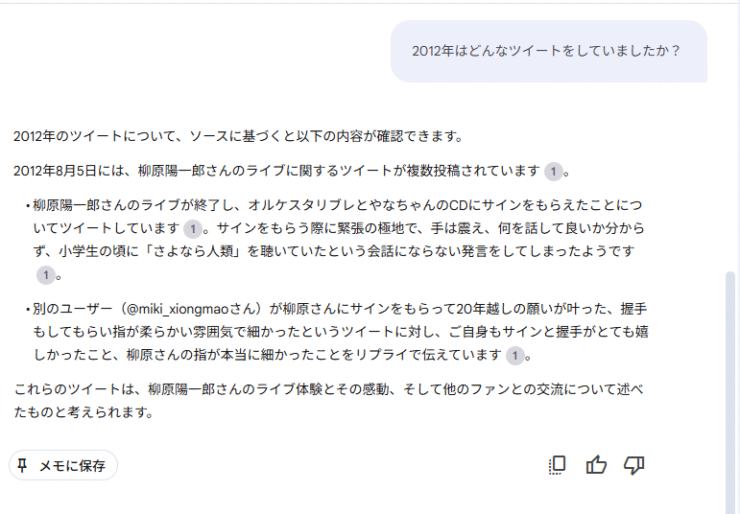
「昔はどんなことをつぶやいていましたか?」
など気になることをきいてみてください。
過去のツイートをまとめてくれるので、自分を解析できます!
まとめ|X(Twitter)ユーザにはNotebookLMは超便利!過去の思いだし、ツイート分析にも使える
以上、NotebookLMにX(Twitter)全ツイートを読み込ませて自分Botを作る方法の紹介でした!
Xだと実は過去の全ツイートを保存できることを知ったのがつい最近。どうせならNotebookLMに読み込ませたい!とおもったのがこの作業のきっかけでした。
「ダウンロードすればすぐに取り込めるかな?」
と思ったのですが、そうはいかず(苦笑)
途中スクリプトが必要になりましたが、Geminiのおかげで全工程を土日で済ますことができました。
スクリプトを作るところなんて、1年前だったら構想だけで終わっていたはず(確信)
Geminiのおかげでできることがどんどん増えてうれしい限りです。
ぜひ、X(Twitter)を使っている方は、過去の振り返り、自分Botの作成に大役立ちですので、ぜひ活用してみてください!
スクリプトがうごかないとかありましたら、Xの方にコメントをよろしくお願いします!